2021-06-05编译原理实验:中间代码生成
点此下载源代码
实验所给文法如下:
\begin{array}{lcl}
program & \to & block\\
block & \to & \{\;decls\;stmts\;\}\\
decls & \to & decls\;decl\;|\;\varepsilon\\
decl & \to & type\;\textbf{id}\;;\\
type & \to &
type\;[\;\textbf{num}\;]\;|\;\textbf{basic}\\
stmts & \to & stmts\;stmt\;|\;\varepsilon\\
stmt & \to & \textbf{id}=expr\;;\\
& | & \textbf{if}\;(\;bool\;)\;stmt\\
& | &
\textbf{if}\;(\;bool\;)\;stmt\;\textbf{else}\;stmt\\
& | & \textbf{while}\;(\;bool\;)\;stmt\\
& | &
\textbf{do}\;stmt\;\textbf{while}\;(\;bool\;)\;;\\
& | & \textbf{break}\;;\\
bool & \to & bool\;||\;join\;|\;join\\
join & \to &
join\;\&\&\;equality\;|\;equality\\
equality & \to &
equality==rel\;|\;equality\;\text{!=}\;rel\;|\;rel\\
rel & \to & expr<expr\\
& | & expr<=expr\\
& | & expr>expr\\
& | & expr>=expr\\
& | & expr\\
expr & \to & expr+term\\
& | & expr - term\\
& | & term\\
term & \to & term\,*\,unary\\
& | & term\;/\;unary\\
& | & unary\\
unary & \to & !\;unary\;|\;-unary\;|\;factor\\
factor & \to &
(\;expr\;)\;|\;\textbf{id}\;|\;\textbf{num}
\end{array}
其中 \textbf{basic}
包括 int, float, char, bool 四种类型。
1 改写文法
1.1 修改错误
由于在 type
中定义了数组类型,但是赋值表达式中未体现,因此这里不实现数组类型,将
decl 改为
decl\to \textbf{basic}\;\textbf{id}\;;
由于 expr
中只涉及四则运算、负数、取反,没有布尔表达式的求值和逻辑运算,因此也将
||、\&\&、>、>=、<、<= 放入 expr 的运算中。
由于最后的 factor
只可以推出 \textbf{num},即整数,然而
\textbf{basic}
中也支持浮点、字符、布尔型,因此需要新定义一个终结符
\textbf{const}
表示所有常量。
1.2 改为二义文法
由于二义文法更为精简,且和教材上给的大部分中间代码生成的语法制导定义符合,因此可将原先的文法改为等价的二义文法。首先将
bool 改为如下:
\begin{array}{lcl}
bool & \to & bool\;||\;bool\\
& | & bool\;\&\&\;bool\\
& | & !\;bool\\
& | & (\;bool\;)\\
& | & expr<expr\\
& | & expr<=expr\\
& | & expr>expr\\
& | & expr>=expr\\
& | & expr\\
\end{array}
之后将 expr
改为如下:
\begin{array}{lcl}
expr & \to & expr\;||\;expr\\
& | & expr\;\&\&\;expr\\
& | & expr<expr\\
& | & expr<=expr\\
& | & expr>expr\\
& | & expr>=expr\\
& | & expr+expr\\
& | & expr-expr\\
& | & expr\,*\,expr\\
& | & expr\;/\;expr\\
& | & !\;expr\\
& | & -\;expr\\
& | & (\;expr\;)\\
& | & \textbf{id}\\
& | & \textbf{const}
\end{array}
通过指定运算符的优先级和结合性解决二义文法的移入-规约和规约-规约冲突,在grammar.y规定优先级和结合性如下:
%left OR
%left AND
%left EQ NE
%left LT LE GT GE
%left '+' '-'
%left '*' '/'
%right INV NOT
其中 INV 为取负数,NOT 为取逻辑非。
1.3 错误恢复
为了在识别到语法错误时,yacc
不立刻退出,而是继续进行翻译并发现剩下可能的错误,这里在
stmt
中加入了错误产生式:
stmt\to\textbf{error}\;;
Yacc
会在遇到错误时,一直向前看,直到遇到分号(即这条错误语句结束)后,将前面的错误规约为
\textbf{error},之后接着翻译后面的内容,从而实现错误恢复。
1.4 综合属性
由于 yacc 采用自底向上的 LR
翻译方案,因此设置每个非终结符和终结符具有如下的综合属性,在types.h中定义为yystack结构体:
typedef struct yystack
{
char name[MAXLEN];
constant_val val;
type type;
int addr;
goto_list *t_list;
goto_list *f_list;
goto_list *n_list;
} yystack;
#define YYSTYPE yystack
其中
name | 终结符 \textbf{id}
的名称 |
val | 终结符 \textbf{const} 的常量值 |
type | 终结符和非终结符的类型,有 int, float, char,
bool |
addr | 非终结符对应的临时变量所在的地址 |
t_list | 条件为真时,待回填目标地址的跳转指令列表,对应教材的
truelist |
f_list | 条件为假时,待回填目标地址的跳转指令列表,对应教材的
falselist |
n_list | 该语句结束时,待回填目标地址的跳转指令列表,对应教材的
nextlist |
2 词法分析
在lexer.l中,对于 \textbf{basic}
终结符,设置相应的类型属性并返回:
int { yylval.type = INT; return BASIC; }
float { yylval.type = FLOAT; return BASIC; }
char { yylval.type = CHAR; return BASIC; }
bool { yylval.type = BOOL; return BASIC; }
对于常量 \textbf{const},也设置相应的类型,并根据不同类型用不同的方法解析常量值。整数和浮点数通过atoi和atof实现,字符型取字符串的第二个字符(第一个是单引号),而布尔型则直接设置:
true { yylval.type = BOOL; yylval.val.boolean = true; return CONST; }
false { yylval.type = BOOL; yylval.val.boolean = false; return CONST; }
{num} { yylval.type = INT; yylval.val.num = atoi(yytext); return CONST; }
{real} { yylval.type = FLOAT; yylval.val.real = atof(yytext); return CONST; }
{char} { yylval.type = CHAR; yylval.val.ch = yytext[1]; return CONST; }
对于 \textbf{id},直接将匹配结果复制到
name 属性,其类型需要句法分析时才能确定。
{id} { strcpy(yylval.name, yytext); return ID; }
匹配标识符、整数、浮点数、字符的正则表达式定义如下,支持浮点数的
E 表示法。
id [A-Za-z][0-9A-Za-z]*
num [0-9]+
real [0-9]+(\.[0-9]+)?(E[+-]?[0-9]+)?
char '.'
3 标识符和常量
3.1 符号表
在types.h中定义标识符、符号表和相关函数如下:
typedef struct symbol
{
char name[MAXLEN];
type type;
int addr;
int width;
struct symbol *next;
} symbol;
typedef struct symbol_list
{
symbol *head;
struct symbol_list *prev;
int begin;
int end;
} symbol_list;
symbol *new_symbol(symbol_list *list, char *name, type type);
symbol *find_symbol(symbol_list *list, char *name);
symbol *find_local_symbol(symbol_list *list, char *name);
symbol_list *new_symbol_list(symbol_list *prev, int addr);
void print_symbol_list(symbol_list *list);
void delete_symbol_list(symbol_list *list);
其中,标识符结构体记录了标识符的名称、类型、所在地址、占据的内存宽度信息,并记录下一个符号的指针,形成链表。由于标识符的定义可以出现在不同的
block 中,且最里层的
block
可以引用当前层以及上层 block
的所有已定义的标识符,因此需要保存符号表的上一级符号表指针prev。
通过修改 block
的产生式,实现不同层级符号表的动态创建和删除:
\begin{array}{ll}
block\to \{\;begin\;decls\;stmts\;end\;\}\\
begin\to\varepsilon & \{\;slist =
new\_symbol\_list();\;\}\\
end\to\varepsilon &
\{\;delete\_symbol\_list(slist);\;\}
\end{array}
其中slist为全局变量,表示当前最外层的
block 的符号表。
grammar.y中具体实现如下:当第一次建立符号表时,需要指定符号表的起始地址。这里用SYMBOL_BEGIN表示,为
1000。之后的符号表从上一级符号表的末尾地址开始。当符号表被释放前,调用print_symbol_list打印当前的符号表。
block : '{' begin decls stmts end '}'
begin :
{
if (slist == NULL)
slist = new_symbol_list(NULL, SYMBOL_BEGIN);
else
slist = new_symbol_list(slist, slist->end);
}
end :
{
symbol_list *slist2 = slist;
if (error == 0)
print_symbol_list(slist2);
slist = slist2->prev;
delete_symbol_list(slist2);
}
3.2 常量表
常量表与符号表类似,但是只需要一个全局常量表clist即可,从地址编号
3000(CONSTANT_BEGIN)开始,不需要保存层级关系,相关函数定义如下:
constant *new_constant(constant_list *list, constant_val val, type type);
constant *find_constant(constant_list *list, constant_val val, type type);
constant_list *new_constant_list(int addr);
void print_constant_list(constant_list *list);
void delete_constant_list(constant_list *list);
3.2 标识符声明和引用
标识符是在句法分析到声明(declaration)时加入到符号表的。因为这时候才可以知道标识符的类型。
decl\to\textbf{basic}\;\textbf{id}\;;\qquad\{\;new\_symbol(slist,\,\textbf{id}.name,\,\textbf{basic}.type);\;\}
其中new_symbol函数创立一个新标识符,并通过当前的符号表信息指定新标识符的地址,通过类型确定新的标识符占据的宽度。在插入到符号表时,还应考虑是否有重复定义的标识符。因为内层同名的标识符会被外层覆盖,因此只需查找当前层的符号表即可,通过find_local_symbol函数实现当前层的符号表查找。语义规则的具体实现在grammar.y中如下:
decl : BASIC ID ';'
{
if (find_local_symbol(slist, $2.name) == NULL)
new_symbol(slist, $2.name, $1.type);
else
{
char msg[MAXLEN];
sprintf(msg, "duplicate declearation of symbol \"%s\"", $2.name);
yyerror(msg);
}
}
引用标识符时,将标识符的属性赋值给当前的非终结符即可:
expr\to\textbf{id}\qquad\begin{array}{l}\{\;expr.type=\mathbf{id}.type;\\\;\;expr.addr=\textbf{id}.addr;\;\}\end{array}
当然也要检查符号是否已经被定义,否则报错,但是可以立刻插入一个新的符号进行错误恢复处理,具体实现如下:
expr : ID
{
symbol *id = find_symbol(slist, $1.name);
if (id == NULL)
{
char msg[MAXLEN];
sprintf(msg, "undeclared symbol \"%s\"", $1.name);
yyerror(msg);
id = new_symbol(slist, $1.name, INT);
}
$$.type = id->type;
$$.addr = id->addr;
}
3.3 常量的引用
对于常量,出现时需要同时加入到全局常量表clist并将其属性赋值给非终结符:
expr\to\textbf{const}\qquad\begin{array}{l}\{\;expr.type=\mathbf{const}.type;\\\;\;expr.addr=new\_constant(clist,\,\textbf{const}.val,\,\textbf{const}.type);\;\}\end{array}
针对重复引用相同常量的问题,在new_constant的函数内部加入了对重复常量的判断。当常量值和类型均相同时,直接返回原先的常量。具体实现与标识符的引用类似。
4 四元组和三地址码
4.1 四元组表
四元组由运算符 op,参数 arg1,arg2,结果
result(arg3)构成。在types.h中定义四元组和四元组列表结构体如下:
typedef struct quadruple
{
int op;
int arg1;
int arg2;
int arg3;
char code[4 * MAXLEN];
} quadruple;
typedef struct quadtable
{
quadruple *buf;
int size;
int bufsize;
} quadtable;
quadtable *new_quadtable();
void print_quadtable(quadtable *table);
void delete_quadtable(quadtable *table);
其中四元组的code字段用于存放三地址码。四元组表的buf用于存放四元组。用于向四元组表中插入四元组的代码,并且生成对应四元组的中间代码。
4.2 增量翻译
使用增量翻译的方式,实现教材上的 gen() 函数。定义如下,其中
arg1、arg2 和 arg3 均为参数的内存地址。
void gen(quadtable *table, symbol_list *slist, constant_list *clist, int op, int arg1, int arg2, int arg3)
该函数具体实现步骤如下。首先,四元组表的大小采用动态内存分配的方式,如果大小不够,则在插入时进行realloc:
if (table->size == table->bufsize)
{
table->bufsize += MAXLEN;
table->buf = realloc(table->buf, table->bufsize);
}
之后,依次进行赋值,插入当前的四元组。如果
arg1、arg2、arg3 的值为
-1,则说明未使用到该参数,或者该参数待回填。
quadruple *t = table->buf + table->size;
t->op = op;
t->arg1 = arg1;
t->arg2 = arg2;
t->arg2 = arg2;
t->arg3 = arg3;
插入后,需要生成该条四元组对应的中间代码。中间代码的地址为当前四元组表的大小加上代码的起始地址CODE_BEGIN,这里设为
100。首先通过arg_name函数查找符号表和常量表,将
arg1、arg2 和 arg3
从内存地址转成对应的符号名称或者常量的字符串表示。如果
arg 的值为 -1,对应空字符串,用于后续的回填。
int addr = table->size + CODE_BEGIN;
char code1[MAXLEN];
char code2[MAXLEN];
char code3[MAXLEN];
arg_name(code1, slist, clist, t->arg1);
arg_name(code2, slist, clist, t->arg2);
arg_name(code3, slist, clist, t->arg3);
之后,根据运算符的不同,生成不同形式的三地址中间代码。因为使用了回填法,中间代码采用每行一个标号,而非
L0、L1 的形式。
switch (t->op)
{
case movi:
case movf:
case movc:
case movb:
sprintf(t->code, "%d:\t%s = %s\n", addr, code3, code1);
break;
case addi:
case addf:
sprintf(t->code, "%d:\t%s = %s + %s\n", addr, code3, code1, code2);
break;
...
case and:
sprintf(t->code, "%d:\t%s = %s && %s\n", addr, code3, code1, code2);
break;
...
case eq:
sprintf(t->code, "%d:\t%s = %s == %s\n", addr, code3, code1, code2);
break;
...
case invi:
case invf:
sprintf(t->code, "%d:\t%s = -%s\n", addr, code3, code1);
break;
case not:
sprintf(t->code, "%d:\t%s = !%s\n", addr, code3, code1);
break;
case ftoi:
case ctoi:
case btoi:
sprintf(t->code, "%d:\t%s = (int)%s\n", addr, code3, code1);
break;
...
case jmp:
sprintf(t->code, "%d:\tgoto %s\n", addr, code3);
break;
...
case jle:
sprintf(t->code, "%d:\tif %s <= %s goto %s\n", addr, code1, code2, code3);
break;
}
这里定义了运算符的枚举类型,mov 系列为赋值运算,add
系列为加法运算,inv 系列为取负数运算,to
系列为类型转换运算,j 系列为跳转和分支指令。后面的
i、f、c、b 后缀对应 int、float、char、bool
类型。如果分支指令需要回填,由于 -1
地址对应的字符串为空字符串,可以直接在原先的字符串后覆盖换行符并追加内容。
5 表达式翻译
5.1 临时变量
用于实现教材的 \textbf{new}\;Temp()。首先,维护全局变量temp_count表示当前临时变量的下标。之后生成临时变量名,并和new_symbol一样的方式将其加入到当前的符号表中,最后返回生成的临时变量的地址:
int new_temp(symbol_list *list, type type)
{
symbol *id = malloc(sizeof(symbol));
sprintf(id->name, "_t%d", temp_count++);
id->type = type;
id->width = type_width[type];
id->addr = list->end;
list->end += id->width;
id->next = list->head;
list->head = id;
return id->addr;
}
5.2 类型转换
用于实现教材的 widen() 函数和 max() 函数。
在types.h中定义了如下的枚举类型和转换矩阵conv,对应类型转换的
op,例如conv[INT][FLOAT] = conv[0][1] = itof,即表示整数转浮点数的指令。-1
表示无需转换。
typedef enum type
{
INT,
FLOAT,
CHAR,
BOOL
} type;
int conv[4][4] = {
{-1, itof, itoc, itob},
{ftoi, -1, ftoc, ftob},
{ctoi, ctof, -1, ctob},
{btoi, btof, btoc, -1}};
之后,编写widen函数。该函数首先根据转换前后的类型判断是否需要转换,如果不需要转换,直接返回原来的参数地址,否则通过new_temp添加一个新的中间变量,并通过gen生成一条类型转换的中间代码,返回中间变量的地址。
int widen(quadtable *table, symbol_list *slist, constant_list *clist, int addr, type type1, type type2)
{
int op = conv[type1][type2];
if (op != -1)
{
int arg3 = new_temp(slist, type2);
gen(table, slist, clist, op, addr, -1, arg3);
return arg3;
}
return addr;
}
接下来,定义了max数组,表示两个类型的数值进行四则运算时,结果的类型应为如何,用于为上述类型转换提供依据。
int max[4][4] = {
{INT, FLOAT, INT, INT},
{FLOAT, FLOAT, FLOAT, FLOAT},
{INT, FLOAT, CHAR, INT},
{INT, FLOAT, INT, BOOL}
};
例如max[CHAR][FLOAT] = MAX[2][1] = FLOAT,即字符类型和浮点类型运算后的结果应是浮点类型。
5.3 四则运算
以加法为例:
expr\to
expr_1+expr_2\qquad\begin{array}{l}\{\;expr.type=max(expr_1.type,\,expr_2.type);\\
\;\;expr_1.addr=widen(expr_1.addr,\,expr_1.type,\,expr.type);\\
\;\;expr_2.addr=widen(expr_2.addr,\,expr_2.type,\,expr.type);\\
\;\;expr.addr=\textbf{new}\;Temp();\\
\;\;gen(expr.addr\;'\texttt{=}'\;expr_1.addr\;'\texttt{+}'\;expr_2.addr);\;\}\end{array}
首先,需要通过max数组确定结果的类型。之后,通过widen函数对源操作数进行类型转换(如果需要)。并新建一个中间变量保存表达式的结果,并将该中间变量的地址赋值给非终结符
expr
的地址属性。最后,通过gen函数增量翻译该语句,生成中间代码。具体实现如下:
expr : expr '+' expr
{
$$.type = max[$1.type][$3.type];
int arg1 = widen(table, slist, clist, $1.addr, $1.type, $$.type);
int arg2 = widen(table, slist, clist, $3.addr, $3.type, $$.type);
int arg3 = new_temp(slist, $$.type);
gen(table, slist, clist, _add[$$.type], arg1, arg2, arg3);
$$.addr = arg3;
}
其中_add数组用于根据类型确定采用哪条加法指令,即addi还是addf。减法、乘法、除法均类似,只是gen中的运算符不同。
5.4 布尔运算
由于这里的布尔运算出现在 expr 的产生式,而非 bool
的产生式中,因此只需考虑布尔运算的值。与四则运算类似,但是
expr.type
预先指定为BOOL,而非使用max数组确定。
5.5 单目运算符和括号
对于取逻辑非操作,也是将类型预先设为BOOL,而对于取负数操作,则将类型设为操作数和INT的最大值,这是因为对于浮点数,取反之后还是浮点数,对于整数、字符、布尔类型,取反之后会变成正数。同时,由于只有一个操作数,因此在使用gen增量翻译的时候,需要将arg2设为
-1。
对于括号,则更简单,直接将属性原封不动的赋值给产生式左部的非终结符即可:
expr\to(\;expr_1\;)\qquad\begin{array}{l}\{\;expr.type=expr_1.type;\\\;\;expr.addr=expr_1.addr;\;\}\end{array}
具体实现如下:
expr : '!' expr %prec NOT
{
$$.type = BOOL;
int arg1 = widen(table, slist, clist, $2.addr, $2.type, $$.type);
int arg3 = new_temp(slist, $$.type);
gen(table, slist, clist, not, arg1, -1, arg3);
$$.addr = arg3;
}
| '-' expr %prec INV
{
$$.type = max[$2.type][INT];
int arg1 = widen(table, slist, clist, $2.addr, $2.type, $$.type);
int arg3 = new_temp(slist, $$.type);
gen(table, slist, clist, _inv[$$.type], arg1, -1, arg3);
$$.addr = arg3;
}
| '(' expr ')'
{
$$.type = $2.type;
$$.addr = $2.addr;
}
5.6 赋值语句
表达式计算完成后,可能需要将其赋值给已定义的标识符。但是
这里仍然涉及类型转换,需要通过widen将表达式的类型转换成标识符本身的类型(如果需要),并生成赋值的中间代码:
stmt\to\textbf{id}=expr\qquad\{\;gen(\textbf{id}\;'\texttt{=}'\;widen(expr.addr,\,expr.type.\,\textbf{id}.type);\;\}
此外,还需要考虑标识符是否已定义。如果在所有的符号表中均为查询到,则报错,但是可以立即新建一个标识符进行错误恢复。具体实现如下:
stmt : ID '=' expr ';'
{
$$.n_list = NULL;
symbol *id = find_symbol(slist, $1.name);
if (id == NULL)
{
char msg[MAXLEN];
sprintf(msg, "undeclared symbol \"%s\"", $1.name);
yyerror(msg);
id = new_symbol(slist, $1.name, INT);
}
int arg1 = widen(table, slist, clist, $3.addr, $3.type, id->type);
int arg3 = id->addr;
gen(table, slist, clist, _mov[id->type], arg1, -1, arg3);
}
其中_mov用于根据类型确定是哪条移动(赋值)指令,有movi、movf、movc、movb。
6 控制流翻译
6.1 回填技术
在types.h中定义goto_list类型,用于回填表结构,即t_list、f_list、n_list(对应教材上的
truelist、falselist、nextlist)。其中存放待回填目标地址的跳转指令的地址列表。并定义相关函数,前两个new_goto_list和merge_goto_list分别对应教材上的
makelist()、merge() 函数。
typedef struct goto_list
{
int addr;
struct goto_list *next;
} goto_list;
goto_list *new_goto_list(int addr);
goto_list *merge_goto_list(goto_list *list1, goto_list *list2);
void delete_goto_list(goto_list *list);
同时,实现教材的回填函数 backpatch()
如下:对于给定的回填表和回填地址,访问位于四元表中的四元组,修改其跳转指令的目的地址(第三个参数arg3),并且修改已经生成的中间代码,在后面追加回填地址的字符串形式:
void backpatch(quadtable *table, goto_list *list, int addr)
{
while (list != NULL)
{
quadruple *t = table->buf + list->addr;
t->arg3 = addr;
sprintf(t->code + strlen(t->code) - 1, "%d\n", addr);
list = list->next;
}
}
6.2 布尔表达式
对于布尔表达式,需要为 bool 非终结符维护 truelist 和 falselist。采用布尔运算符“短路”的方法翻译布尔表达式,为此需将产生式进一步做适当的改写:
\begin{array}{ll}
bool\to bool_1\;||\;M\;bool_2 &
\begin{array}{l}\{\;backpatch(bool_1.falselist,\,M.addr);\\\;\;bool.truelist=merge(bool_1.truelist,\,bool_2.truelist);\\\;\;bool.falselist=bool_2.falselist;\;\}\end{array}\\\\
bool\to bool_1\;\&\&\;M\;bool_2 &
\begin{array}{l}\{\;backpatch(bool_1.truelist,\,M.addr);\\\;\;bool.truelist=bool_2.truelist;\\\;\;bool.falstlist=merge(bool_1.falselist,\,bool_2.falstlist);\;\}\end{array}\\\\
bool\to\;!\;bool_1 &
\begin{array}{l}\{\;bool.truelist=bool_1.falselist;\\\;\;bool.falselist=bool_1.truelist;\;\}\end{array}\\\\
bool\to(\;bool_1\;) &
\begin{array}{l}\{\;bool.truelist=bool_1.truelist;\\\;\;bool.falselist=bool_1.falselist;\;\}\end{array}\\\\
M\to\varepsilon & \{\;M.addr=nextinstr;\;\}
\end{array}
其中 nextinstr
为下一条指令地址,即当前四元组表的长度加上代码段首地址table->size + CODE_BEGIN。通过引入标记符号
M
记录与和或运算的第二个布尔表达式对应的代码的起始地址。
以或运算为例说明“短路”的方法。首先,回填 bool_1 的条件为假的跳转地址为
bool_2
的起始地址,因为或运算第一个为假,第二个还可能为真,无法直接得到结果。但是将
bool_1
条件为真的跳转地址和 bool_2 的合并,均为 bool
的条件为真的跳转地址,这样当 bool_1 确实为真时,可以跳过
bool_2
的判断,直接跳转。具体实现如下:
M :
{ $$.addr = table->size + CODE_BEGIN; }
bool : bool OR M bool
{
backpatch(table, $1.f_list, $3.addr);
$$.t_list = merge_goto_list($1.t_list, $4.t_list);
$$.f_list = $4.f_list;
}
| bool AND M bool
{
backpatch(table, $1.t_list, $3.addr);
$$.t_list = $4.t_list;
$$.f_list = merge_goto_list($1.f_list, $4.f_list);
}
| '!' bool %prec NOT
{
$$.t_list = $2.f_list;
$$.f_list = $2.t_list;
}
| '(' bool ')'
{
$$.t_list = $2.t_list;
$$.f_list = $2.f_list;
}
6.3 条件表达式
布尔运算也能推出条件表达式。条件表达式又分两种,一种是通过关系运算符
\textbf{rel},即 ==、!=、>、>=、<、<=。另一种是直接将表达式作为布尔类型求值。翻译如下:
\begin{array}{ll}
bool\to expr_1\;\textbf{rel}\;expr_2 &
\begin{array}{l}\{\;type=max(expr_1.type,\,expr_2.type);\\\;\;expr_1.addr=widen(expr_1.addr,\,expr_1.type,\,type);\\\;\;expr_2.addr=widen(expr_2.addr,\,expr_2.type,\,type);\\\;\;bool.truelist=makelist(nextinstr);\\\;\;bool.falselist=makelist(nextinstr+1);\\\;\;gen('\texttt{if}'\;expr_1.addr\;\textbf{rel}\;expr_2.addr\;'\texttt{goto
\_}');\\\;\;gen('\texttt{goto
\_}');\;\}\end{array}\\\\
bool\to expr &
\begin{array}{l}\{\;type=max[expr_1.type][\textbf{bool}];\\\;\;expr_1.addr=widen(expr_1.addr,\,expr_1.type,\,type);\\\;\;bool.truelist=makelist(nextinstr);\\\;\;bool.falselist=makelist(nextinstr+1);\\\;\;gen('\texttt{if}'\;expr_1.addr\;'\texttt{==}'\;\textbf{true}\;'\texttt{goto
\_}');\\\;\;gen('\texttt{goto
\_}');\;\}\end{array}
\end{array}
对于第一种情况,也需要将关系运算符两边的参数通过max和widen化成同类型,再进行比较。之后将条件成立的goto语句加入
truelist
回填表,将下一条(条件不成立)的goto语句加入
falselist 回填表。
对于第二种情况,首先将该表达式转换成 bool
类型,并将其与true这一常量进行是否相等的比较,其余与第一种情况类似。两种情况的具体实现如下,第一种情况以大于等于为例:
bool : expr GE expr
{
int arg1 = widen(table, slist, clist, $1.addr, $1.type, max[$1.type][$3.type]);
int arg2 = widen(table, slist, clist, $3.addr, $3.type, max[$1.type][$3.type]);
$$.t_list = new_goto_list(table->size + CODE_BEGIN);
$$.f_list = new_goto_list(table->size + CODE_BEGIN + 1);
gen(table, slist, clist, jge, arg1, arg2, -1);
gen(table, slist, clist ,jmp, -1, -1, -1);
}
| expr
{
int arg1 = widen(table, slist, clist, $1.addr, $1.type, BOOL);
int arg2 = new_constant(clist, (constant_val)true, BOOL)->addr;
$$.t_list = new_goto_list(table->size + CODE_BEGIN);
$$.f_list = new_goto_list(table->size + CODE_BEGIN + 1);
gen(table, slist, clist, jeq, arg1, arg2, -1);
gen(table, slist, clist ,jmp, -1, -1, -1);
}
6.4 分支语句
除了布尔表达式,还需要对一般的表达式语句维护 nextlist,即该语句结束时,待回填目标地址的跳转指令列表。为此,需要引入上述提到的
M 标记,并新增 N 标记:
\begin{array}{ll}
stmt\to\textbf{if}\;(\;bool\;)\;M\;stmt_1 &
\begin{array}{l}\{\;backpatch(bool.truelist,\,M.addr);\\\;\;stmt.nextlist=merge(bool.falstlist,\,stmt_1.nextlist);\;\}\end{array}\\\\
stmt\to\textbf{if}\;(\;bool\;)\;M_1\;stmt_1\;N\;\textbf{else}\;M_2\;stmt_2
&
\begin{array}{l}\{\;backpatch(bool.truelist,\,M_1.addr);\\\;\;backpatch(bool.falselist,\,M_2.addr);\\\;\;stmt.nextlist=merge(stmt_1.nextlist,\,merge(N.nextlist,\,stmt_2.nextlist));\;\}\end{array}\\\\
M\to\varepsilon & \{\;M.addr=nextinstr;\;\}\\\\
N\to\varepsilon &
\begin{array}{l}\{\;N.nextlist=makelist(nextinstr);\\\;\;gen('\texttt{goto
\_}');\;\}\end{array}
\end{array}
以 if-else 为例。回填布尔表达式条件为真的地址为 stmt_1
的起始地址,回填布尔表达式条件为假的地址为 stmt_2 的起始地址。同时通过
N
标记生成一条跳转指令,使得 stmt_1 执行完后可以跳转到
if-else 语句末尾,而不是进入下一条 else 语句。最后,合并
stmt_1、N 和 stmt_2
的下一条指令的地址的回填表,成为 stmt
的下一条指令的地址的回填表。具体实现如下:
N :
{
$$.n_list = new_goto_list(table->size + CODE_BEGIN);
gen(table, slist, clist, jmp, -1, -1, -1);
}
stmt : IF '(' bool ')' M stmt
{
backpatch(table, $3.t_list, $5.addr);
$$.n_list = merge_goto_list($3.f_list, $6.n_list);
}
| IF '(' bool ')' M stmt N ELSE M stmt
{
backpatch(table, $3.t_list, $5.addr);
backpatch(table, $3.f_list, $9.addr);
$$.n_list = merge_goto_list(merge_goto_list($6.n_list, $7.n_list), $10.n_list);
}
这里需要注意的是,需要将 N 的产生式放在 stmt 前,因为原先的 if-else
语句二义性问题(移入 else- 规约单独的 if
语句冲突),yacc 会默认选择移入,从而正确解决 else
的二义性。但新引入 N
后,变为了规约 N- 规约单独的 if 语句冲突。yacc
在处理这种冲突时,会按照产生式的顺序决定优先级,因此需要将
N 的产生式放在 stmt 前,以确保优先规约 N,移入接下来的 else
语句。
6.5 循环语句
除了和分支语句基本相似的条件判断之外,为了实现循环的
break,需要额外定义一个全局的栈break_lists,用于在循环开始存放各个层级的循环中的
break 语句地址,因此需要在每个循环前引入标记 Q,该标记的作用就是将一个新的
breaklist
压入栈。一旦遇到 break,就将该栈的栈顶与新产生的 goto
指令的地址合并。循环结束时,将该栈顶弹出,加入到 stmt 的 nextlist 中。
\begin{array}{ll}
stmt\to\textbf{while}\;Q\;M_1\;(\;bool\;)\;M_2\;stmt_1
&
\begin{array}{l}\{\;backpatch(stmt_1.nextlist,\,M_1.addr);\\\;\;backpatch(bool.truelist,\,M_2.addr);\\\;\;stmt.nextlist=merge(bool.falselist,\,breaklists.pop());\\\;\;gen('\texttt{goto}'\;M_1.addr);\;\}\end{array}\\\\
stmt\to\textbf{do}\;Q\;M_1\;stmt_1\;M_2\;\textbf{while}\;(\;bool\;)\;;
&
\begin{array}{l}\{\;backpatch(bool.truelist,\,M_1.addr);\\\;\;backpatch(stmt_1.nextlist,\,M_2.addr);\\\;\;stmt.nextlist=merge(bool.falstlist,\,breaklists.pop());\;\}\end{array}\\\\
stmt\to\textbf{break}; &
\begin{array}{l}\{\;stmt.nextlist=\textbf{null};\\\;\;breaklists.top=merge(breaklists.top,\,makelist(nextinstr));\\\;\;gen('\texttt{goto
\_}');\;\}\end{array}\\\\
Q\to\varepsilon &
\{\;breaklists.push(\textbf{null});\;\}
\end{array}
同时,对于 while 循环,需要额外在循环末尾生成一条
goto 指令,跳转到循环首。而 do-while
则不用,直接根据布尔表达式的 truelist
决定。具体实现如下:
Q :
{ break_lists[tos++] = NULL; }
stmt : WHILE Q M '(' bool ')' M stmt
{
backpatch(table, $8.n_list, $3.addr);
backpatch(table, $5.t_list, $7.addr);
$$.n_list = merge_goto_list($5.f_list, break_lists[--tos]);
gen(table, slist, clist, jmp, -1, -1, $3.addr);
}
| DO Q M stmt WHILE M '(' bool ')' ';'
{
backpatch(table, $8.t_list, $3.addr);
backpatch(table, $4.n_list, $6.addr);
$$.n_list = merge_goto_list($8.f_list, break_lists[--tos]);
}
| BREAK ';'
{
$$.n_list = NULL;
if (tos == 0)
yyerror("\"break\" statement doesn't match any loop");
else
{
break_lists[tos - 1] = merge_goto_list(break_lists[tos - 1], new_goto_list(table->size + CODE_BEGIN));
gen(table, slist, clist, jmp, -1, -1, -1);
}
}
6.6 回填 nextlist
上述由控制流语句生成的 nextlist,是暂时没有确定该语句的下一条语句的地址,因此记录下来,留在之后回填。因此,要在每条语句结束时,通过
M
记录下一条语句开始的地址,并执行回填操作:
stmts\to
stmts\;stmt_1\;M\qquad\{\;backpatch(stmt_1.nextlist,\,M.addr);\;\}
具体实现如下:
stmts : stmts stmt M
{ backpatch(table, $2.n_list, $3.addr); }
同时,针对其他的 stmt 产生式,如 stmt\to\textbf{id},stmt\to block,应将其 nexlist
设为空,防止merge_goto_list时指针未初始化为空而报错。
7 运行结果
7.1 编译
在终端通过以下命令编译,其中yacc使用-v命令输出状态转换图信息到y.output:
lex lexer.l
yacc -v -d grammar.y
cc types.c y.tab.c -ly -ll
在yacc编译时,提示有 5
个移入-规约冲突,22
个规约-规约冲突,可以在y.output中查看冲突的具体情况。5
个移入-规约冲突是规约 bool\to
expr 和移入 AND、OR
的冲突,应优先移入,因此采取默认动作。21
个规约-规约冲突是 bool
和 expr
有部分相同的产生式所致,因为 bool 的产生式放在 expr
的产生式之前,因此优先规约 bool,即优先生成跳转代码,而非进行布尔表达式求值。还有
1 个规约-规约冲突是上述提到的 if-else
二义性因为引入了标记 N
所致,解决方法是把产生式 N 放在前面,优先规约 N 并移入 else。
如果将下面的测试样例存为test.c:
{
int i;
int sum;
i = 2;
while (i <= 100)
{
sum = sum + i;
i = i + 2;
}
}
运行以下命令即可得到输出结果:
./a.out < test.c
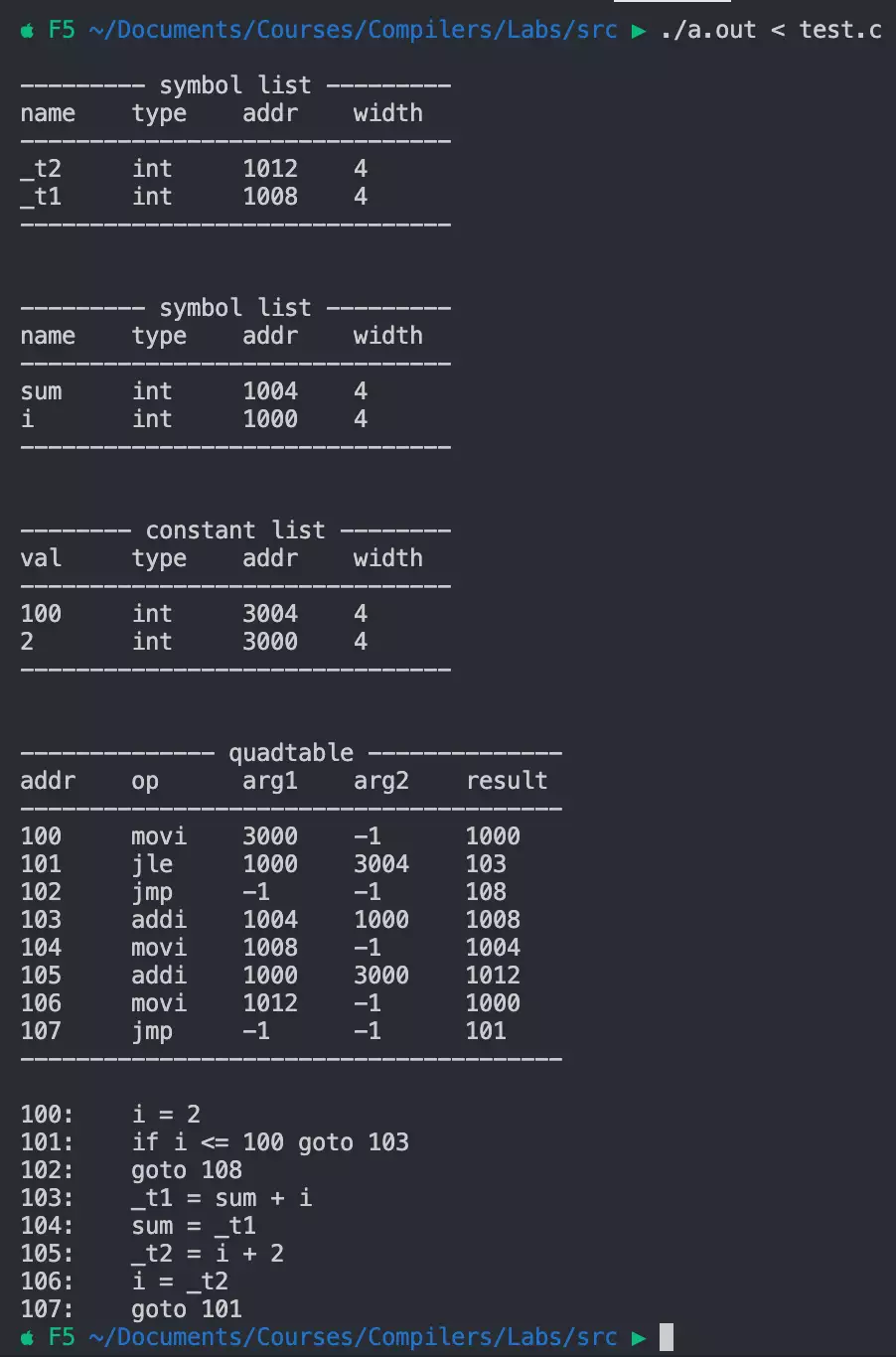
程序依次按照层次顺序打印符号表,全局常量表,四元组表,最后打印四元组对应的中间代码。
7.2 符号表和常量表测试
对于以下程序
{
int a; float b; char c;
a = 137; b = 3.14159;
if (a == 137)
{
bool d; int e;
d = true; e = 137;
}
else
{
char d; float e;
d = '*'; e = 3.14159;
}
c = '*';
}
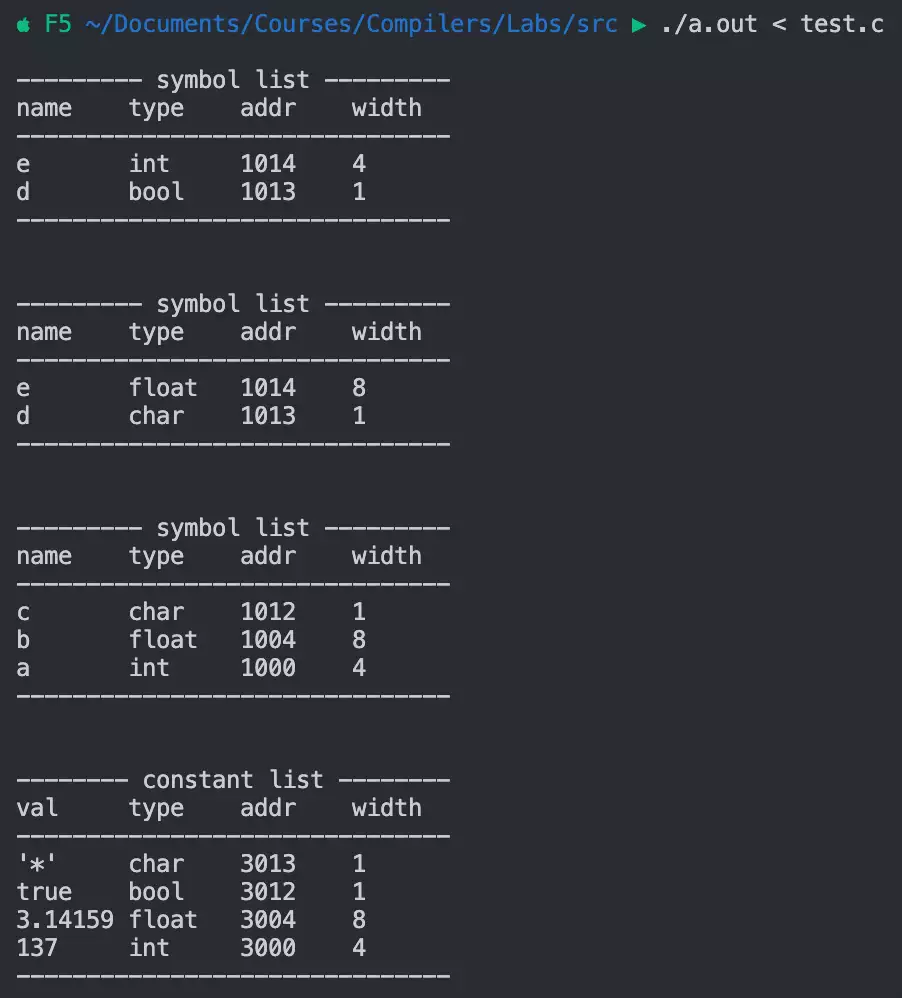
程序输出如下的符号表和常量表,可以看到三个块分为 3
个符号表,并且不同块内的符号重名没有影响。常量表也没有重复插入相同的常量:
7.3 表达式翻译测试
使用如下测试代码,涉及运算符优先级、布尔表达式求值、类型转换:
{
int a;
float b;
bool result;
a = 1 * 1;
b = a / 2 + 1;
result = b != 1.5 && a == 1;
}
翻译结果如下:
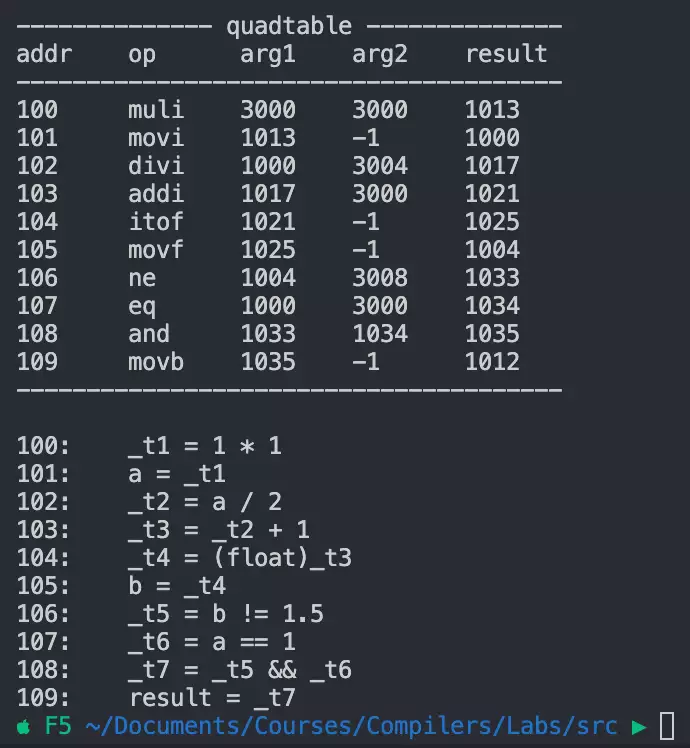
可以看到,对于a / 2这种整数除法,翻译没有问题,结果仍然是整数,直到赋值给
b 时才转成浮点数。
7.4 控制流翻译测试
使用如下测试代码,涉及
if、if-else、while、do-while、break
的翻译,以及短路代码的体现:
{
int i; int j; float sum;
i = 0; j = 0;
while(true)
{
i = i + 1;
do
{
sum = sum + 1.0 / i;
if (sum > 3) break;
else j = j + 1;
} while (j < 100);
if (i >= 100 || sum > 3) break;
}
}
结果如下:
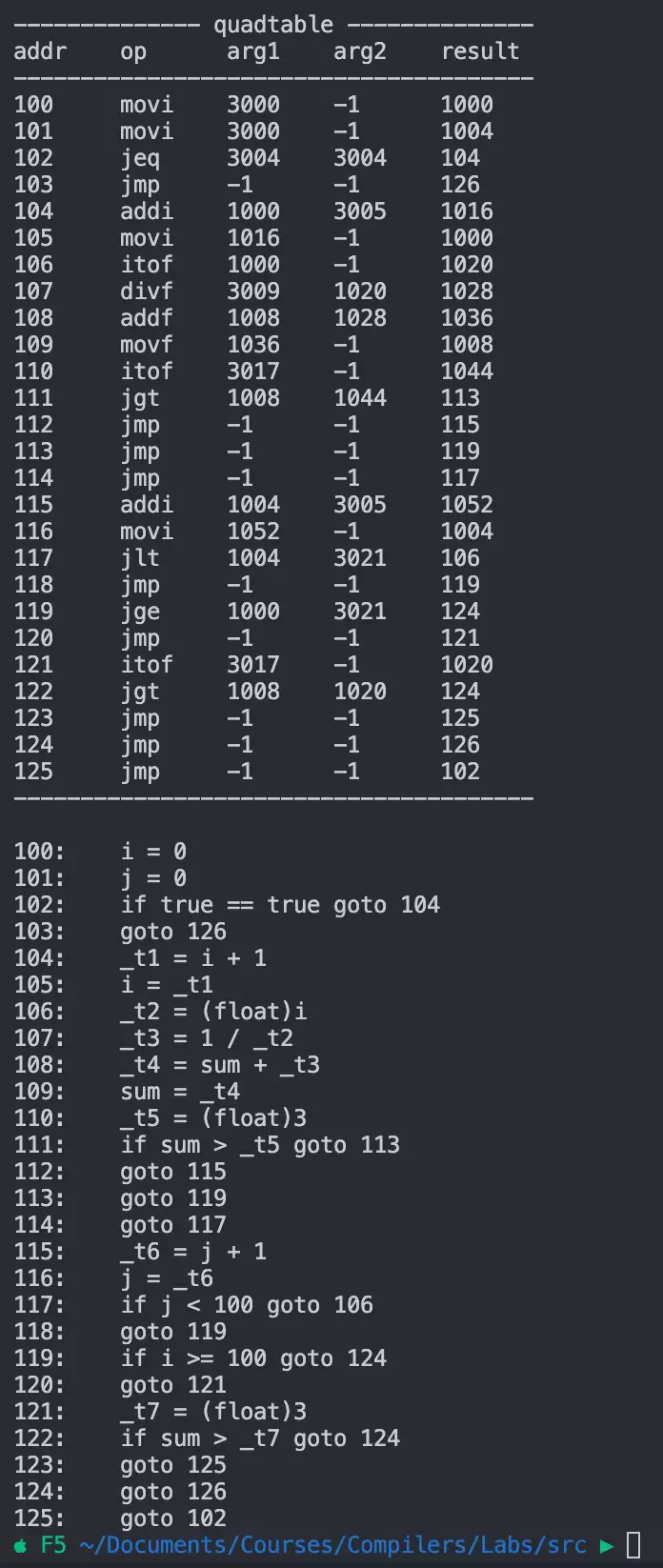
可以看到,这些goto语句均正确的回填。
7.5 错误恢复测试
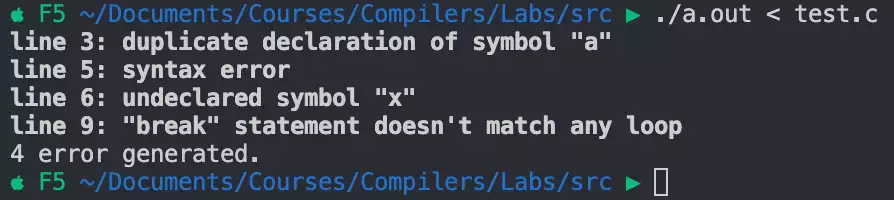
用以下这个充满错误的程序测试,首先第三行对a的重复定义,第四行缺分号,第
6
行对未定义的变量x的引用,以及不在任何循环语句内的break:
{
int a; int b;
float a;
a = 1
b = 0;
if (x < 1)
{
a = a - 1;
break;
}
}
程序输出如下,可见输出了全部的错误:
点此下载源代码